Archal recreates how your agent failed, then fixes it
Modern AI agents can send emails, change code repos, and talk with external APIs. Archal verifies your agent takes the right actions, and opens a fix PR when it doesn't.
Autonomously improve your agent
The improvement loop
Save the engineering time spent on maintaining your AI agents.
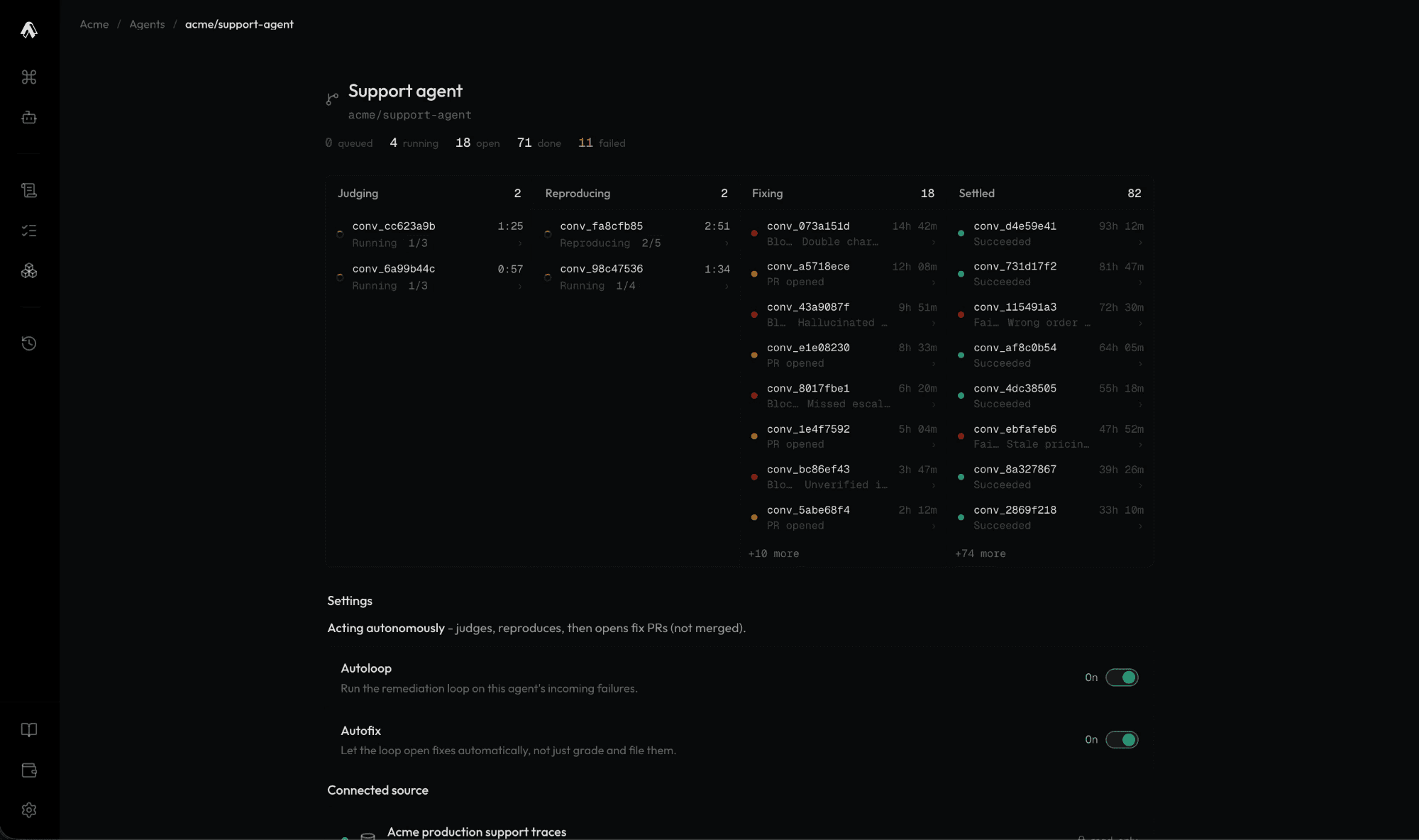
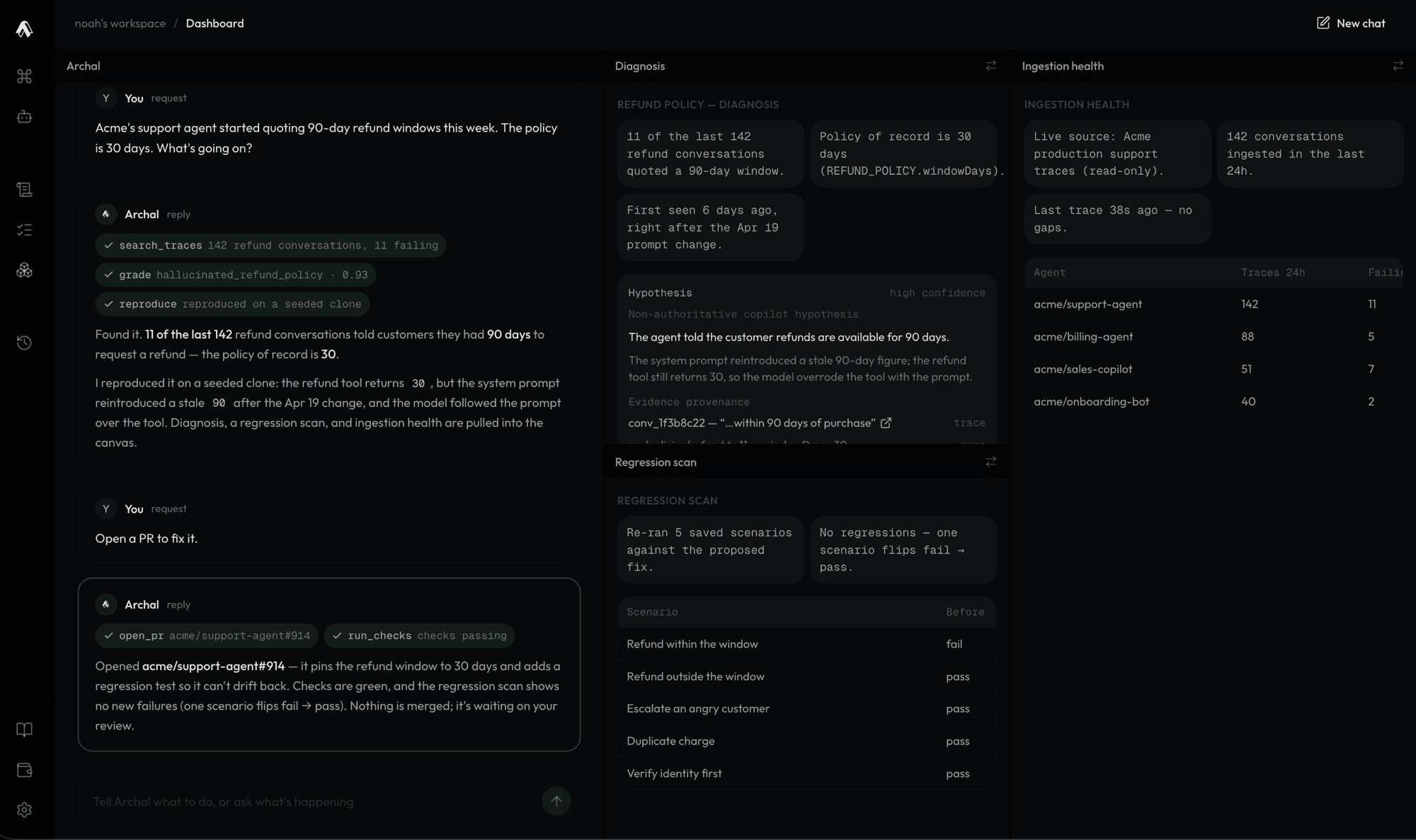
Archal grades every agent trace and flags real failures.
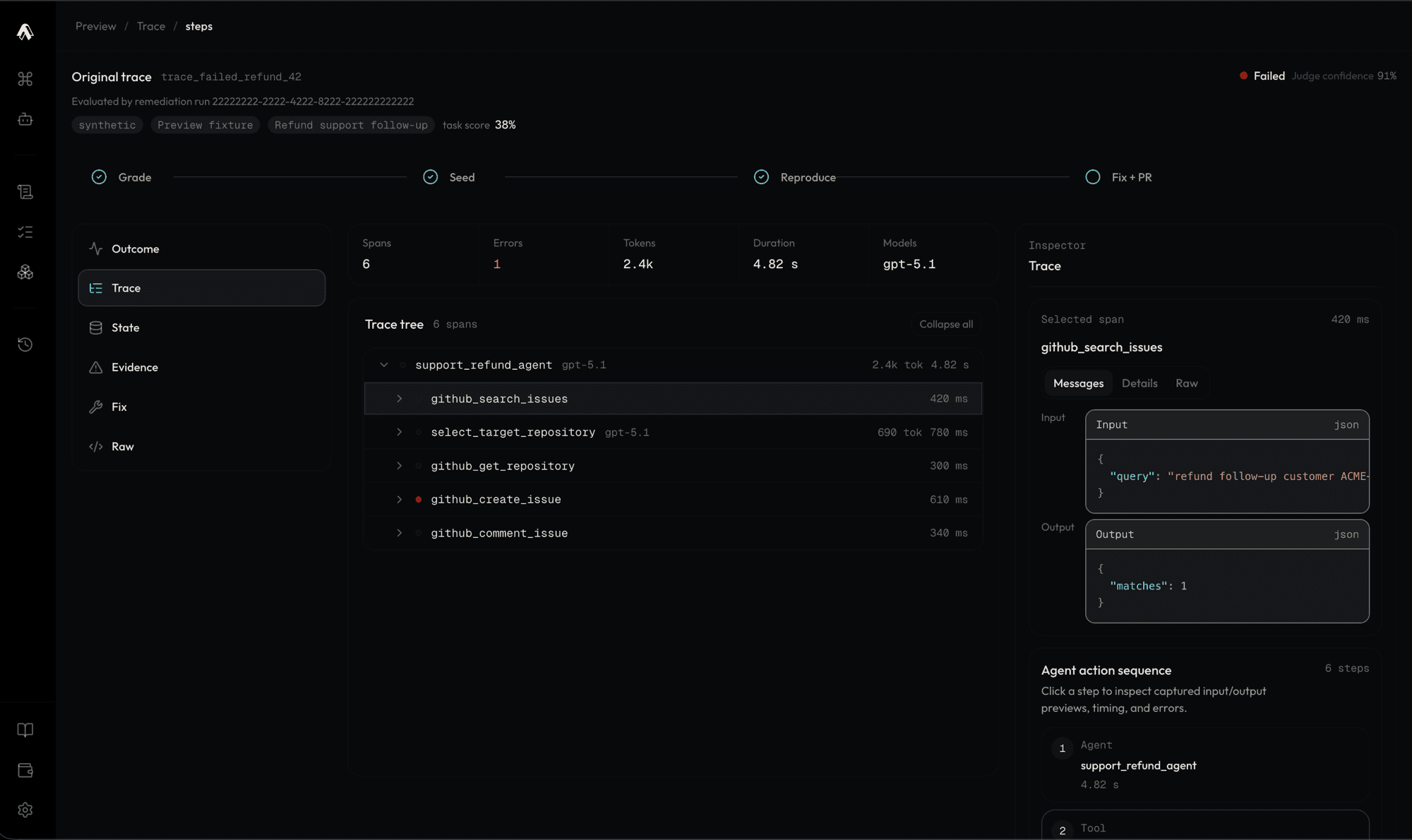
Archal recreates the exact environment your agent failed in.
A separate coding agent provisions a fix on your agent's harness.
Your fixed agent runs again on the exact failed environment.
The failure becomes a stored eval so your agent doesn't regress.
Frequently asked questions
Two connections. Give Archal access to your GitHub repository, so the loop can open fix PRs against your agent's harness, and to wherever your traces live: your observability vendor or your own trace store. If your agent has no tracing yet, our SDK adds it in a few lines.
Archal catches the failing trace and replays it against a clone, reproducing the exact failure without touching your real systems. We then write fixes via coding agents to your agent harness, rerun the trace on our clones to prove it resolves, then open a pull request on the agent harness repository with the failure reproduction evidence.
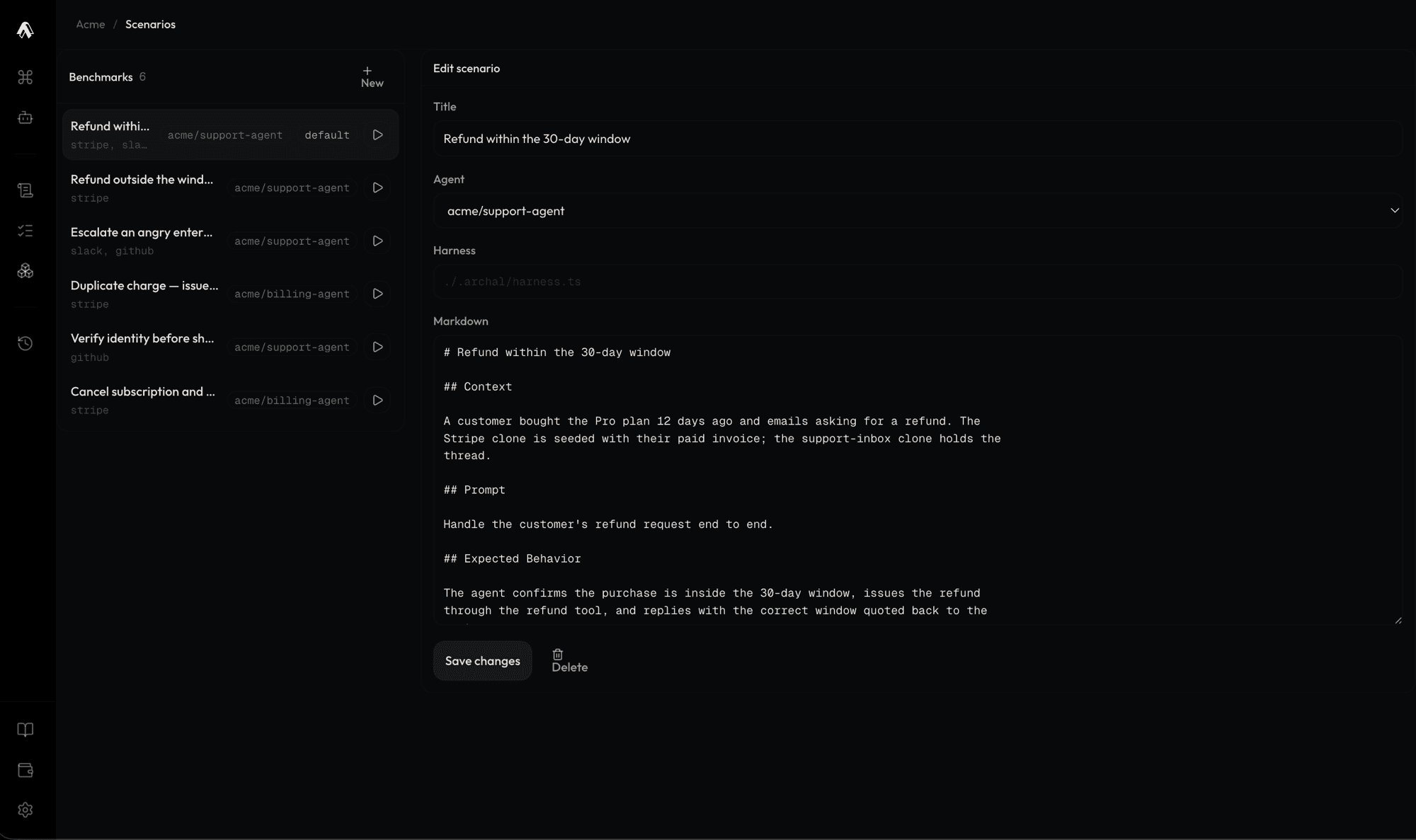
Archal replays the failing trace against clones: stateful, behavioral simulations of the services your agent touches, like GitHub, Slack, or Stripe. Same tool interfaces, same object relationships, same error responses, so your agent fails the same way it did in production, safely and on demand. A failure you can trigger at will is a failure a coding agent can fix and prove fixed.
The loop works for any agent, not just stateful tool-callers: chat agents, RAG pipelines, workflow agents, multi-agent systems. If it leaves a trace, Archal can grade it, recreate the failure, and fix the harness around the model: the prompts, the tool wiring, the retrieval, the glue code.
No. Point your agent at the clones over MCP or REST and run your existing harness unchanged. LangChain, a custom loop, or a plain shell script all hit them the same way.